设计一个 Redis 集群都挂了?你如何做?
最近在面试中遇到一个有意思的场景。面试官问:"如果你项目中的 Redis 集群整个都挂了,这时你要如何处理应对呢?"
候选人很自信地回答:"这个没关系的,因为 Redis 有 RDB 和 AOF 两种持久化方式,在 Redis 4.0 支持了 RDB + AOF 的混合持久化,所以挂了也没事。等 Redis 集群重启之后,数据是可以很快恢复过来的。"说完还习惯性地摸了摸后脑勺,似乎对自己的回答很满意。
面试官摇了摇头:"我的意思是,如果 Redis 集群挂了,那系统中所有请求就都落在数据库上了,数据库应该也很快会被打挂吧。而一旦数据库挂了,那系统就整体不可用了。"
候选人明显有些慌乱:"哦,没事的,我们系统的 QPS 没有那么高,不会把数据库打挂的。"
面试官继续追问:"既然你们系统中的 QPS 没这么高,那为什么要用 Redis 来扛请求呢?"
候选人:"这......"
面试官又补充道:"另外,就算把 Redis 集群中的数据恢复了,大概率也不能用了。因为在 Redis 集群挂了的这个时间段,仍然会有很多数据修改或删除的请求打过来,Redis 集群中的数据并没有随之进行更改或删除,那就会出现脏数据的情况。"
“
💡 核心问题从这段对话可以看出,候选人的答案并不是面试官想要的。面试官希望听到的是,当 Redis 集群挂了的时候,如何从保障系统可用性的角度,给出范围可控且快速止损的解决方案,而不仅仅是背诵"Redis 持久化"相关的八股文。
正确的应对姿势:三步走策略
接下来我们言归正传,说说"Redis 集群挂了"这个场景的整体处理步骤。可能会比大家所认知的要复杂一些,但理解起来并不困难。
第一步:启动限流降级,守住最后防线
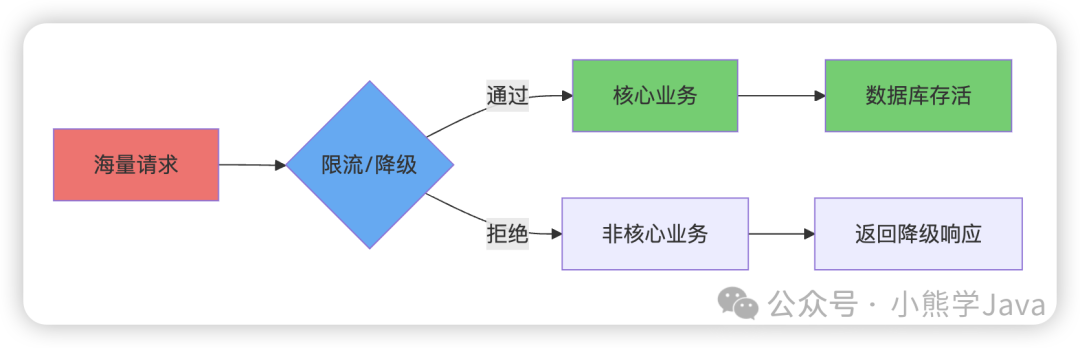
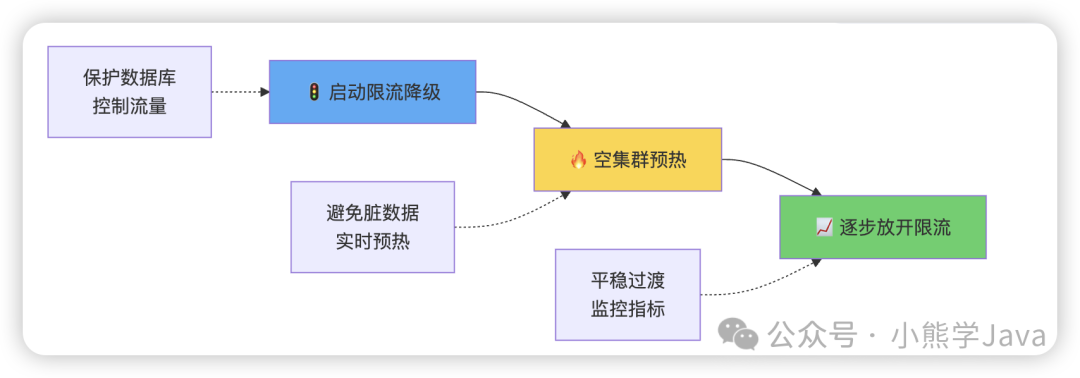
当 Redis 集群挂了的情况下,我们需要迅速启用限流或降级策略,把系统接收请求的数量和质量,控制在其所能承载处理的范围之内。说白了就是,让失去 Redis 集群支撑的业务系统,不要被外部流量直接击垮。
关于限流
限流的目的是保护系统不被超出其处理能力的请求冲垮,通过拒绝请求的方式保证系统的可用性。这个理念在日常生活中也很常见:
- 🚇 北上广深的地铁限流
- 🏛️ 故宫每天限制 3000 名游客
- 🎫 演唱会门票限量发售
限流的关键在于阈值设置。我们需要在系统的业务低峰期,以真实流量回放、并递增加压的方式进行压测:
| 压测倍数 | 系统表现 | 是否可用 |
|---|---|---|
| 1 倍 | 正常 | ✅ |
| 1.5 倍 | 正常 | ✅ |
| 2 倍 | 响应变慢 | ⚠️ |
| 2.5 倍 | 部分超时 | ⚠️ |
| 3 倍 | 大量失败 | ❌ |
探查系统所能承载的最大容量后,将限流阈值设置为其峰值容量的 70%~ 85%,既保证安全边际,又不过度浪费资源。因此,如果我们所负责的系统足够重要,是需要专门压测"Redis 集群挂了"这个场景的。
关于降级
服务降级是指当系统出现高负载或异常时,通过牺牲部分非核心功能的方式,保证系统核心功能的可用性。这是一种"弃车保帅"的策略。

“
⚠️ 重要提醒"Redis 集群挂了"这个场景的降级策略,我们需要通过配置中心以修改参数的方式操作降级,而不是现场修改业务代码进行 Hotfix 的方式。这点一定要切记,否则会把一个本应不存在的故障拖到真实发生。
🤔 如何选择?
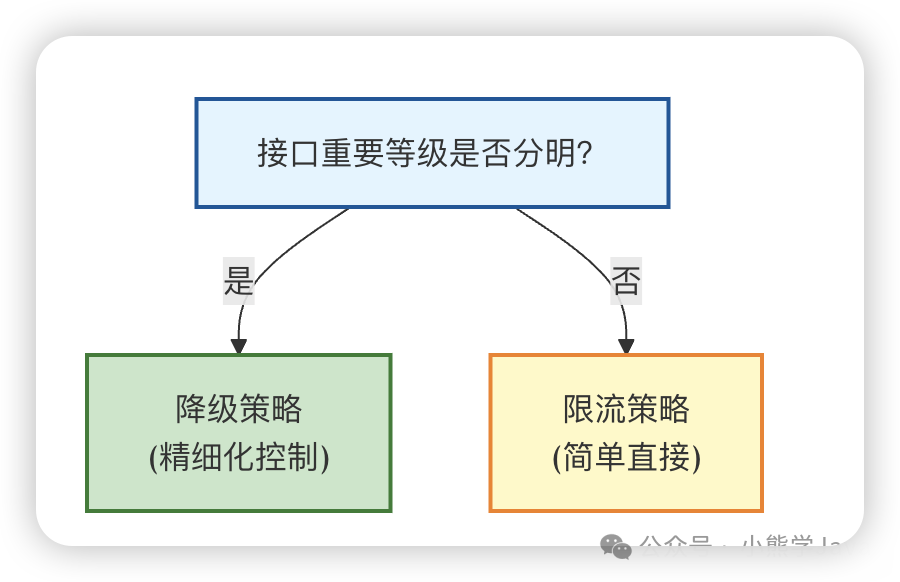
- 如果系统中接口的重要等级非常分明,我们尽量选择通过"降级"的策略来解决问题
- 如果系统中接口的重要等级并不分明,我们就索性简单直接地走"限流"的策略
🔥 第二步:空集群预热,避免脏数据陷阱
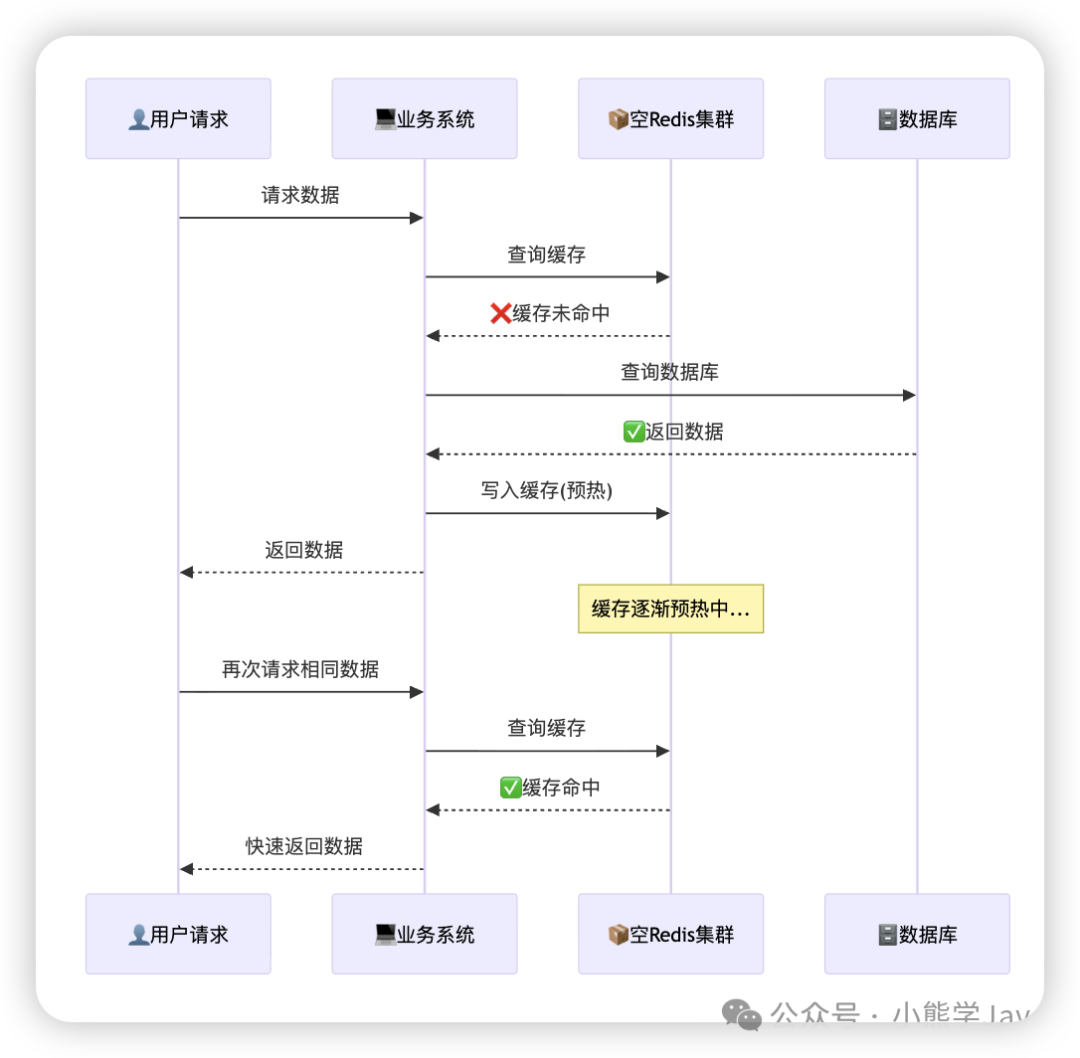
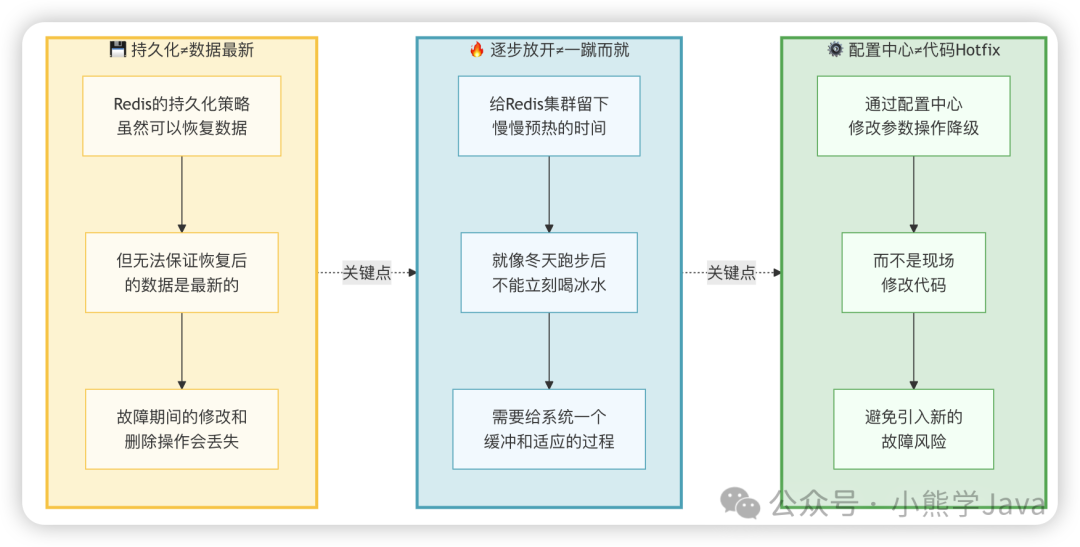
之前我们说了,在"Redis 集群挂了"这个时间段,仍然会有很多数据修改的请求打过来,Redis 集群中的数据并没有随之更改或删除,那就会出现脏数据的情况。
这种情况下,"部署一个全新的 Redis 集群(不加载旧数据),通过用户实时请求逐步预热缓存",投入到生产环境的使用中,通过将用户实时请求的数据吃进缓存的方式将其慢慢预热。
“
⚠️ 切记此时不要把限流或降级一下子放开,因为当前形同虚设的空 Redis 集群,还不能起到保护数据库的作用,数据库容易被瞬间激增的流量打挂。
特殊情况
当然,也有例外的情况,就是该系统存储到 Redis 中的数据只有添加和查询操作,并没有修改和删除操作。这种情况下,可以把挂了的 Redis 集群直接进行数据恢复,恢复完成后即可直接投入生产环境使用。
| 操作类型 | 是否存在 | 能否直接恢复 |
|---|---|---|
| 添加(ADD) | ✅ | ✅ 可以 |
| 查询(GET) | ✅ | ✅ 可以 |
| 修改(UPDATE) | ❌ | ✅ 可以 |
| 删除(DELETE) | ❌ | ✅ 可以 |
| 修改(UPDATE) | ✅ | ❌ 不可以 |
| 删除(DELETE) | ✅ | ❌ 不可以 |
第三步:逐步放开限流降级,平稳过渡
随着 Redis 集群中缓存的数据越来越多,可以将限流或降级逐步放开,直至恢复到正常状态。这个过程就像给系统一个缓冲和适应的时间,不能操之过急。
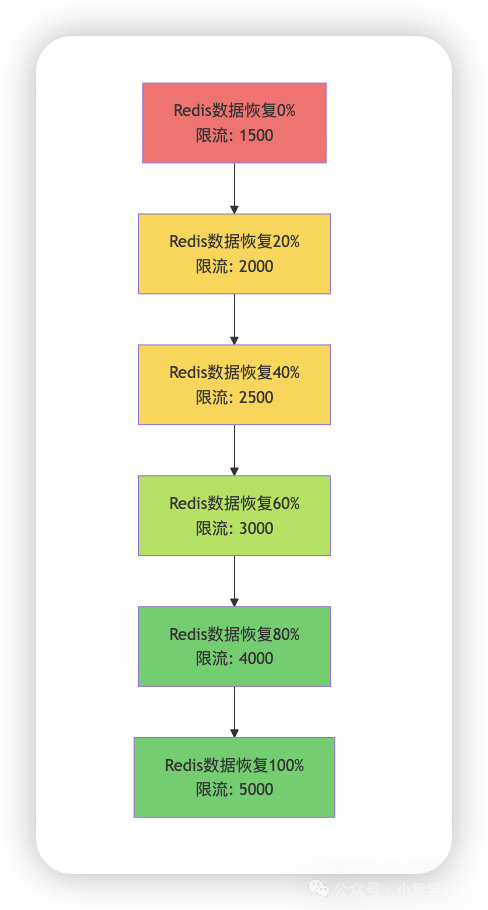
限流场景
在正常状态下,假设我们的系统将限流阈值设置为5000,当 Redis 集群挂了的时候,我们将系统的限流阈值调整到了1500。
当 Redis 新集群中的数据量恢复到正常状态下 20%的时候,我们可以将系统的限流阈值调整到 2000;恢复到 40%的时候,将系统的限流阈值调整到 2500……以此类推。
| Redis 数据恢复进度 | 限流阈值调整 | 说明 |
|---|---|---|
| 0 % | 1500 | 🔴 紧急状态 |
| 20 % | 2000 | 🟡 逐步恢复 |
| 40 % | 2500 | 🟡 继续恢复 |
| 60 % | 3000 | 🟢 接近正常 |
| 80 % | 4000 | 🟢 基本正常 |
| 100 % | 5000 | ✅ 完全恢复 |
降级场景
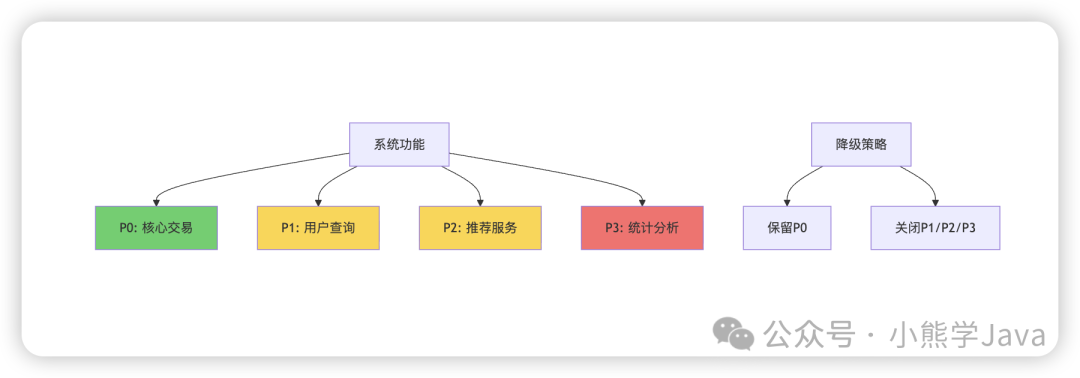
我们系统中的功能等级,按照其重要程度分为P0、P1、P2、P3四个等级。当 Redis 集群挂了的时候,我们将系统降级到只支持 P0 等级的功能。

| Redis 数据恢复进度 | 开放功能等级 | 功能描述 |
|---|---|---|
| 0 % | P0 | 🔴 仅核心交易 |
| 30 % | P0 + P1 | 🟡 增加用户查询 |
| 60 % | P0 + P1 + P2 | 🟢 增加推荐服务 |
| 90 % | P0–P3 | ✅ 全功能恢复 |
当 Redis 新集群中的数据量恢复到正常状态下 30%的时候,我们可以将系统的降级策略调整到支持 P0 和 P1 等级;恢复到 60%的时候,将系统的降级策略恢复到支持 P0、P1 和 P2 等级……以此类推。
“
监控指标此时我们也要重点关注数据库服务器中的各种硬件指标:
- 系统 Load:反映系统整体负载情况
- IOPS:每秒读写次数,判断磁盘压力
- CPU 利用率:避免 CPU 打满
- 内存使用率:防止 OOM
- 慢查询数量:及时发现性能瓶颈
总结
其实对于"Redis 集群挂了"这个场景,首先需要规避的就是"回答姿势不对"的问题,造成被面试官一通追击连问的情况。面试官想听的不是技术原理的背诵,而是你对系统可用性的理解和实战经验。
🎯 三个关键要点
记住这三步走策略
完整流程总结
让我们把整个应对流程串联起来看:
- 发现 Redis 集群挂了 → 立即启动应急预案
- 快速启动限流/降级 → 将流量控制在数据库可承受范围内(阈值设为峰值的 50%-70%)
- 部署空 Redis 集群 → 避免使用旧数据造成脏数据问题
- 监控预热进度 → 观察缓存命中率和数据库压力
- 分阶段放开限流 → 根据预热进度(20%、40%、60%...)逐步调整阈值
- 持续监控指标 → 关注 Load、IOPS、CPU、内存、慢查询等
- 完全恢复正常 → 所有功能恢复,限流阈值恢复到正常值
下次再遇到类似的面试问题,你就知道该怎么回答了。不要只停留在技术原理层面,更要展现出你对系统可用性、故障应对、风险控制的深刻理解。
“
💬 互动话题你在实际工作中遇到过 Redis 集群故障吗?当时是如何处理的?处理过程中有哪些经验教训?欢迎在评论区分享你的经验,一起交流学习~